Vele uren en dagen zwoegen met als resultaat een net niet werkend voorspelmodel, hoe erg is dat? Vooral flink balen, maar zeker geen verspilde tijd. De lessen die je persoonlijk en als organisatie leert zijn minstens zo waardevol als de uitkomst van het project. Werken met data is vooral een kwestie van doen, of het gaat om het maken van een rapportage, dashboard of voorspelmodel.
Geen verklaring voor afwijking
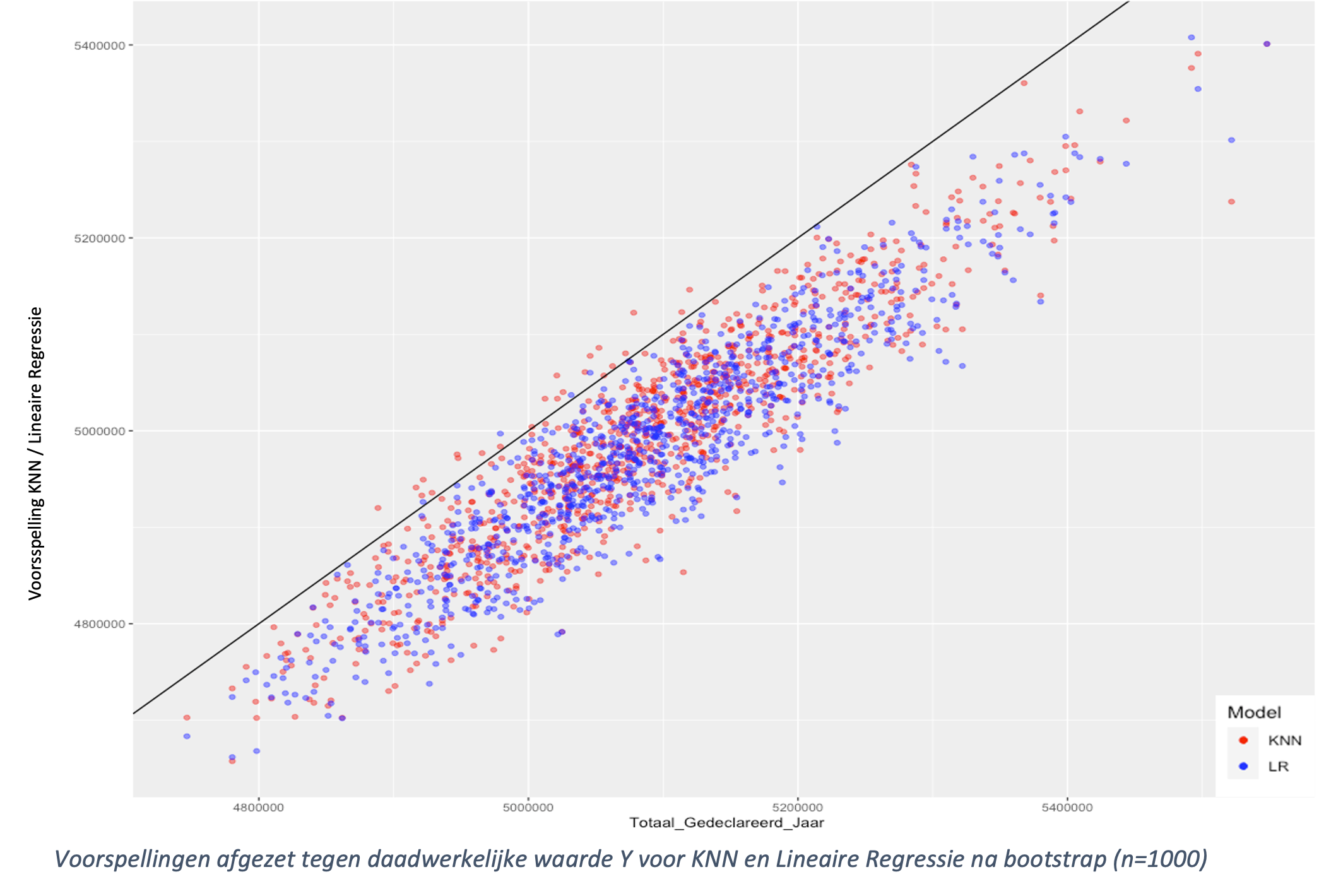
Bij mijn net afgeronde project om de declaraties bij gemeenten op jeugdzorg en Wmo te voorspellen, was dit niet anders. In mijn vorige blog beschreef ik de noodzaak voor vele gemeenten om in november/december inzicht te krijgen in hoeveel ze dat jaar nog aan declaraties binnenkrijgen (vaak nog enkele miljoenen). Kort samengevat ben ik hierin een heel eind gekomen, maar voorspelt het model circa 2% te weinig uitgaven. Zoals je in onderstaand figuur kan zien, zitten bijna alle voorspellingen onder de (zwarte) baseline die de daadwerkelijke uitgave voorstelt. Op een uitzondering na, zijn bijna alle voorspellingen (1000x) te laag. Zonder verklaring voor deze afwijking is het model niet goed bruikbaar. Als je niet weet waarom je afwijkt, kan je namelijk ook geen voorspelling doen op de afwijking. Een volgende keer kan de afwijking dan 0% of 10% procent zijn, zonder dat je dit weet (het blijft een voorspelling van de toekomst die je niet weet). Het fundament moet dus een bepaalde mate van voorspelbaarheid hebben, die nu dus ontbreekt. De puntenwolk hieronder zou dus netjes om zwarte lijn moeten liggen, om een bruikbaar model te hebben.
Inzicht in aard van data
Natuurlijk is er teleurstelling dat het voorspelmodel gemeenten niet direct kan helpen (al zal het zeker wel een goede indicatie geven). Maar als je met een dergelijk voorspelmodel (trede 3 in model van figuur 1) aan de slag gaat, doe je vele inzichten op over de aard van je data. Deze inzichten zijn te gebruiken voor rapportages (trede 1) en monitoring/dashboards (trede 2). Zo kwam ik erachter dat er een groot verschil zit in declaratiegedrag tussen jeugdzorg en Wmo, maar ook tussen productcategorieën (type zorg). Kortweg betekent dit dat de ene beschikking met een waarde van €100.000,- de ander niet is (op de een wordt waarschijnlijk bijvoorbeeld maar 30% uitgegeven en op de ander waarschijnlijk 90%). Dit soort inzichten zijn erg waardevol voor de business. Hierop ontstaan vragen voor beleid en uitvoering: Moeten we anders gaan beschikken bij bepaalde zorgtypen? Kunnen we andere financiële ramingen hierop maken? Presteren sommige zorgaanbieders beter dan anderen?
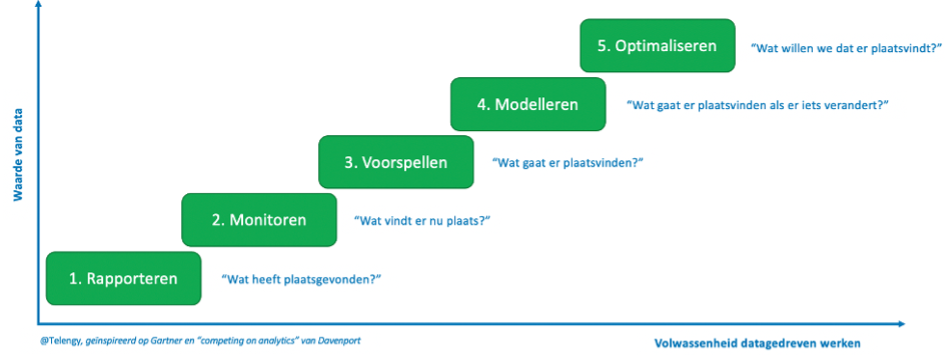
Figuur 1
Een toelichting van het bovenstaande groeimodel vind je hier.
Groei als organisatie
De grootste winst binnen een dataproject zit niet eens op de groei in kennis van je data, maar op groei als organisatie. In een half jaar dat mijn project heeft gelopen, zijn er zo veel inzichten gekomen. Inzichten in processen binnen de keten van onderzoek, valkuilen binnen dataprojecten en de mogelijkheden (en vooral ook onmogelijkheden) met datavoorspellingen. Kennis die je enkel vergaart door te gaan doen. Iedere organisatie op zijn eigen niveau, maar leg de lat vooral niet te laag. Een voorspelmodel zorgt voor versnelling van de niveaus daaronder. Andersom geldt ook rapportages en dashboards verstevigen het fundament van betrouwbare voorspelmodellen en versnelt de doorlooptijd van een project. Kortom, ga aan de slag!
Meer weten?
Voor meer informatie kunt u contact opnemen met Tim van der Pol, adviseur bij Telengy, via tel. nr. 06 21 36 68 58 of via e-mail: t.v.d.pol@telengy.nl.

